この章の目標
・チューリング機械について学ぶ・句構造文法の定義を学ぶ
・帰納的可算言語について学ぶ
・線形有界オートマトンの定義を学ぶ
・単調文法の定義を学ぶ
・文脈依存言語について学ぶ
チューリング機械(TM)
チューリング機械(TM)は入力テープが作業テープの役割を兼ねていてテープ上を行きつ戻りつしながら読み書きでき
テープを必要なら両方向にいくらでも延長できる。
形式的には$M=(Q,\Sigma,\Gamma,\delta,q_0,F)$であって、各々以下の意味を持つ。
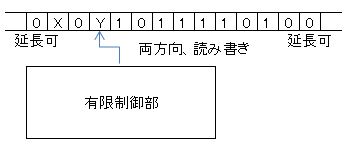
- 状態の有限集合 $Q$
- 入力記号の有限集合 $\Sigma$
- テープ記号の有限集合 $\Gamma\supseteq \Sigma\,\dot\cup\,\{□\}$
- 遷移 $\delta\subseteq (Q-F)\times\Gamma\times\Gamma\times\{L,R\}\times Q$
- 開始状態 $q_0 \in Q$
- 受理状態の集合 $F\subseteq Q$
$(q,X;Y,D,p)\in\delta$($\transition{q}{X;Y,D}\circled{p}$)のとき$M$は、状態$q$でテープ記号$X$を読むと
- テープ記号を$Y$に書きかえ、ヘッドをD方向(左L/右R)に動かし
- 状態$p$に遷移する
TMによる認識と計算
入力$\vect{w}\in\Sigma^*$に対する初期IDを$q_0\vect{w}$と表し、特に$\vect{w}=\varepsilon$ならIDとしては$q_0=q_0□$であると約束する。TM$M$の初期時点表示$q_0\vect{w}$から始まる時点表示列には、以下の3種類の状況が考えられる。
- 受理状態に達して、動作が定義されていないので停止する
- 動作が定義されていない非受理状態とテープ記号に到達し停止する
- 無限に(受理状態に達することなく)動き続ける
- $M$は$\vect{w}$を受理するといい、$M$が認識(受理)する言語を$\mathcal{L}(M):=\{\vect{w}\mid q_0\vect{w}\VDASH{}{*}\alpha q\beta,\ q{\in}F\}$で定義する。
- $M$は入力$\vect{w}$に対し、$\rm{Trim}(\alpha\beta)$を出力すると言い、$M$が計算する入出力関係を$\mathcal{R}(M):=\{(\vect{w},\rm{Trim}(\alpha\beta))|q_0\vect{w}\VDASH{}{*}\alpha q\beta,\ q{\in}F\}\subseteq \Sigma^*\times\Gamma^*$で定義する。ここで$\rm{Trim}(\alpha\beta)$は$\alpha\beta$の両端の空白記号列を(あれば)取り除いたものである。
例.$0^n1^n,\ n{\gt}0$ を受理するTM
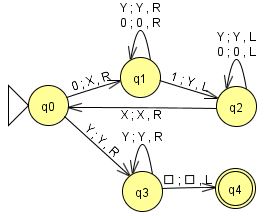 右図のTM(JFLAPファイル)は次のように動いて、入出力関係$\{(0^n1^n,X^nY^n)\mid n\gt 0\}$を計算し、$\{0^n1^n\mid n\gt 0\}$を受理する。
右図のTM(JFLAPファイル)は次のように動いて、入出力関係$\{(0^n1^n,X^nY^n)\mid n\gt 0\}$を計算し、$\{0^n1^n\mid n\gt 0\}$を受理する。
- 状態$q_0$で$0$を$X$に書き換え、右に行って
- 最初に出会った$1$を$Y$に書き換えて左に戻り$X$を見たら右に動いて状態$q_0$に
- $q_0$で$Y$を見た($0$がすべて$X$に書き換わった)ら、右に行って$Y$だけなら受理($q_4$)
q_0,0,X,R,q_1 q_0,Y,Y,R,q_3 q_1,0,0,R,q_1 q_1,Y,Y,R,q_1 q_1,1,Y,L,q_2 q_2,0,0,L,q_2 q_2,Y,Y,L,q_2 q_2,X,X,R,q_0 q_3,Y,Y,R,q_3 q_3,BLANK,BLANK,L,q_accept |
但し、このシミュレータでは、受理状態に入る時ヘッドを動かさずに停止する。
TMの技法
本節では、TMの認識(計算)能力への洞察を得るために、TMを具体的に構成する際に有用な技法をいくつか例示的に紹介する。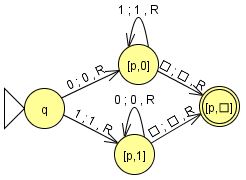
状態への記憶
右図は$01^*\cup 10^*$を認識するTM(JFLAP)である。状態に最初の文字を記憶([p,0]、[p,1])し、[p,0]([p,1])で1(0)を連続して読んで右端に至れば受理する。

多重トラック
右図は、以下を繰返して $\{\vect{w}c\vect{w}\mid \vect{w}{\in}\{0,1\}^*\}$ を認識するTM$M$の説明である。
- セルの文字を状態に記憶しセルに*印を付けた後。右に移動して
- $c$を超えて最初の未照合(*なしの)セルと照合し、
- 一致したらそのセルに*を付けて、最も左の未照合セルに戻る
サブルーチン
あるTMを別のTMの一部として“埋め込む”ことができる。例えば下左図のTM Copyの機能は$\vect{w}q_10^n10^k\overset{*}{\vdash}\vect{w}q_50^n10^{k+n}$であり、それを埋め込んだ下右図のTMは、以下の手順を$i=2,3,\cdots,m$に対して実行し、乗算$(0^m10^n1,0^{mn})$を計算する。
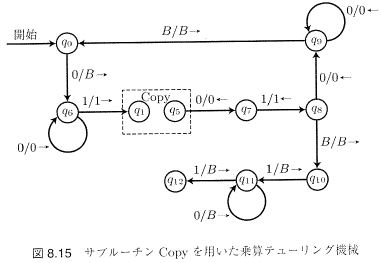
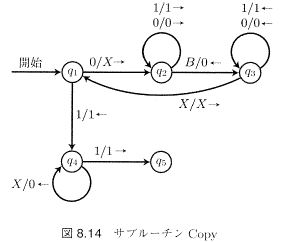
この構成は、加算を使った乗算の帰納的定義 1,$0n=0,$ 2.$mn-(m-1)n+n$ に基づいている。
TMの機能拡張
本節では、必ずしもTMの能力を高めるわけではない機能拡張されたTMを紹介する。これらは本来のTMで実現可能なTMであるが、実際にTMを設計するときに有用なTMである。多テープチューリング機械

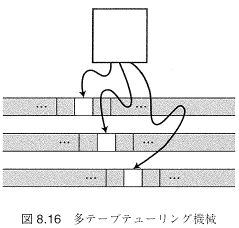 複数のテープとテープヘッドを持ち、そのうちの一本が入力テープであるTM(右図)。1テープTMの多重トラック技法を用いて模倣できる(最右図)。
複数のテープとテープヘッドを持ち、そのうちの一本が入力テープであるTM(右図)。1テープTMの多重トラック技法を用いて模倣できる(最右図)。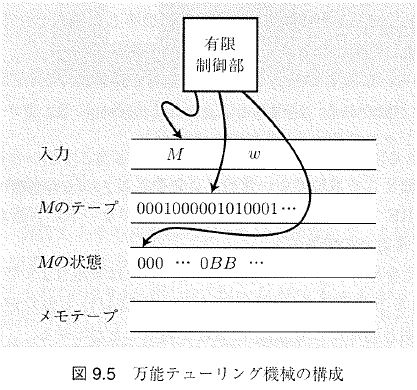 万能チューリング機械 ${\mathcal U}$(右図)
万能チューリング機械 ${\mathcal U}$(右図)${\mathcal U}$は、詳細は後述するが、入力テープ上に書かれたTM$M$の動作規則列$\vect{M}$と入力$\vect{w}$から、
・$M$のテープ内容を保持するテープ
・$M$の状態を記録するテープ
・メモ用テープ
を使用して$M$の動きを模倣する。したがって
$\mathcal{L}(\mathcal{U})=\{\vect{M}\vect{w}\mid Mは\vect{w}を受理する\}$、
$\mathcal{R}(\mathcal{U})=\{(\vect{M}\vect{w},\alpha)\mid Mは(\vect{w},\alpha)を計算する\}$
とできる。ここで$\mathcal{U}$は、$\vect{M}$中で不正な命令記述に出会うと、それを解釈できずに停止する。
具体的に$\mathcal{U}$を設計する前に、考えるべき点がある。$\mathcal{U}$が模倣するTM$M=(Q,\Sigma,\Gamma,\delta,q_1,F)$の$F{\subseteq}Q,\ \Sigma{\subseteq}\Gamma$は有限ではあるがいくらでも大きくなり得るのに対し、$\mathcal{U}$のそれらを、模倣するTMに応じて増やすわけにはいかない。そこで、$\mathcal{U}$が模倣するTMの入力記号はすべて$\Sigma\supseteq \{0,1\}$であると仮定し、$F=\{q_2\}$という本質的でない制限をおく。各々の要素に番号を付けて、$Q{=}\{q_1,q_2,\dots,q_m\},$ $\Gamma{=}\{X_1{=}□,X_2,\dots,X_n\},$ $L{=}D_1,R{=}D_2$とする。$M$の遷移$(q_h,X_i;X_j,D_k,q_l) \in \delta$を$10^h10^i10^j10^k10^l1$という0,1列で表し、それらを全て並べた後ろに11を付けた列($\in (1(0^+1)^3(0\cup 00)10^+1)^+11$ )を$M$の表現といい、$\vect{M}$と表す。$\mathcal{U}$は入力テープに$\vect{M}\vect{w}\in \Sigma^*$を持って開始し、以下のように動作する。なお定義から入力テープの一番左の111までが$\vect{M}$である。
- 「$M$の状態」テープに初期状態を表す0を書き込み、$\vect{w}=X_{i_1}X_{i_2}\cdots X_{i_{|\vect{w}|}}$を0,1列 $0^{i_1}10^{i_2}1\cdots 10^{i_{|\vect{w}|}}1$ に翻訳して「$M$のテープ」テープにコピーする
- 「$M$の状態」が$00$のとき、$\mathcal{U}$は入力を受理して停止する
- 「$M$の状態」が$0^h$で、「$M$のテープ」のヘッド位置から次の1までが$0^i$であるとき、$\mathcal{U}$は$\vect{M}$の中から部分列$10^h10^i10^j10^k10^l1$を探す。見つからなければ停止し、見つかれば「$M$の状態」を$0^l$とし、「$M$のテープ」のヘッド位置の$0^i$を$0^j$に置き換え$k=1(L)か2(R)$にしたがって、そのヘッド位置を移動して(はみ出す場合に□を表す01を追加して)、2.に戻る。
TMの機能制限
本節では、必ずしもTMの能力を低下させるわけではない制限されたTMを紹介する。これらの制限された機械で、本来のTMを模倣できる。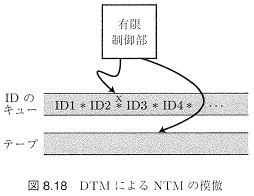 決定性TM(DTM)
決定性TM(DTM)TMの状態$q{\in}Q$とテープ記号$X{\in}\Gamma$に対し、可能な動作(遷移)$\delta(q,X):=\{(Y,D,p)\mid (q,X;Y,D,p){\in}\delta\}$が一意に決まる【$|\delta(q,X)|{\le} 1$を満たす】TMを決定性TM(DTM)という。以下、特に区別するときは非決定性TMをNTM、決定性TMをDTMという。
定理.NTM$M_N$と同じ言語を認識するDTM$M_D$が構成できる
略証.$M_N$の動きは、初期時点表示を根とする木で表される。$M_D$は$M_N$の時点表示の列を保持するテープを別に持ち、それを使って、$M_N$の動作木を幅優先探索(動作ステップの少ない順に探索)する。$M_D$は$M_N$の時点表示に受理状態が現れた時、受理状態に達し停止する。
この議論をそのまま計算能力の比較に適用するには注意が必要である。DTM$M_D$の入力$\vect{w}$に対する出力は、高々1つなのでNTMが計算する関係$\mathcal{R}(M_N,\vect{w}):=\{\alpha\mid (\vect{w},\alpha)\in\mathcal{R}(M_N)\}$を直接計算することはできない。ただし、$\mathcal{R}(M_N,\vect{w})$の要素を(場合によっては無限に)並べ続ける事はDTMでも可能である。
問.関係$\{(1^m,1^{mn})\mid m,n\ge 1\}$を計算するNTMを示せ。
他の制限
TMの機能を以下のように制限しても、認識(計算)能力は変わらない
- 半無限テープTM:テープを右側にしか延長できない。2トラック半(右)無限テープTMで(通常の)両無限テープTMを模倣するには、左端から左に伸ばすときに折返して下の段を使うようにすればよい。
- 2スタック機械:テープの代わりに2本のスタックを持つ機械でTMを模倣するにはテープのヘッド位置から左部分と右部分をそれぞれのスタックに格納すればよい。
- 2計数機械:入力専用テープの他に。スタック記号が(底記号以外に)1種類のみのスタック2本を持つ機械。説明は省略。
パズル.2スタック機械でTMを模倣できることを示せ
句構造文法とTM
文法$G=(\Gamma,\Sigma,S,P)$の規則が、左辺に非終端記号を1個は含むという条件のみ、即ち$\alpha{\to}\beta,\ \alpha{\in}(\Sigma {\cup}\Gamma)^*{-}\Sigma^*, \beta{\in}(\Sigma{\cup}\Gamma)^*$の形の文法を句構造文法という。文法の規則 $\alpha\to\beta$ を適用して、文形式 $\xi\alpha\zeta\in(\Sigma\cup\Gamma)^*$ を $\xi\beta\zeta\in(\Sigma\cup\Gamma)^*$ に置き換えることを導出といい、$\xi\alpha\zeta \Rightarrow \xi\beta\zeta$ と表す。導出$\Rightarrow$の$0$回以上の繰返しで $\xi_0\Rightarrow\xi_1\Rightarrow\xi_2\Rightarrow\cdots\Rightarrow\xi_n,\ n\ge 0$ となるとき $\xi_0\overset{*}\Rightarrow \xi_n$ と表す。特に$n=0$なら$\xi_0\overset{*}\Rightarrow \xi_0$ である。
$\alpha\in(\Sigma\dot\cup\Gamma)^*$に対し$\alpha\overset{*}\Rightarrow \vect{w}\in \Sigma^*$ となるとき、文法$G$で$\alpha$が終端記号列$\vect{w}$を生成(導出)するといい、$\mathcal{L}(G,\alpha):=\{\vect{w}\mid X\overset{*}\Rightarrow \vect{w}\in\Sigma^*\}$を$G$で$\alpha$が生成する言語、$\mathcal{L}(G):=\mathcal{L}(G,S)$ を$G$が生成する言語という。
句構造文法$G$⇒TM$M$の証明のアイディア
$M$は入力$\vect{w}$に対し、$G$による導出の逆(還元)を(非決定的に)実行し、$S$がテープ上に得られれば、受理する。すなわち
 TM$M$⇒句構造文法$G$の証明のアイディア
TM$M$⇒句構造文法$G$の証明のアイディア$G$はその規則を使って、最初に最終状態を含む時点表示を生成し、$M$の動作を逆順に模倣して初期時点表示に戻し、 最後に状態記号を消去する。すなわち
$M$で$q_0\vect{w}\VDASH{}{*}\alpha qX\beta \vdash \alpha Yp\beta\VDASH{}{*} \gamma q_f\delta \iff$
$G$で$S\overset{*}\Rightarrow \gamma q_f\delta\overset{*}\Rightarrow\alpha Yp\beta\Rightarrow\alpha qX\beta\overset{*}\Rightarrow q_0\vect{w}\Rightarrow\vect{w}$
$M$で$q_0w\VDASH{}{*}\alpha qX\beta \vdash \alpha Yp\beta\VDASH{}{*} \gamma q_f\delta \iff G$で$S\overset{*}\Rightarrow \gamma q_f\delta\overset{*}\Rightarrow\alpha Yp\beta\Rightarrow\alpha qX\beta\overset{*}\Rightarrow q_0w\Rightarrow w$
となるように$G$を構成する
可算帰納言語
定理.同値な次の3条件をみたす言語を可算帰納言語という。- 句構造文法(制限なし)で生成される
- (非決定性)チューリング機械で認識される
- 決定性チューリング機械で認識される
可算帰納の意味:数え(並べ)あげが帰納的にできる。
句構造文法$G$が生成する言語は次のように帰納的に定義できる
- 開始記号は$G$で導出される
- $G$で導出さた列に規則を適用した結果は、$G$で導出される
- $G$で導出される終端記号列のみが$G$で生成される
問.1.加算帰納言語は和、反転、準同型写像で閉じていることを示せ。
2.帰納的可算言語は決定性TMで認識されるが、以下で証明されるように補集合演算で閉じていない。何故だと考えられるか。
言語$L$は$L$と$L^\complement$が共に加算帰納的であるとき、$\vect{w}\in L$の判定が帰納的にできることから、判定帰納言語という。
※通常、判定帰納言語は単に帰納言語と呼ばれるが、本稿ではその意味を強調するために判定帰納言語という。
問.全入力で停止するDTMが認識する言語は判定帰納言語と一致することを示せ。
定理.加算帰納言語は補集合で閉じておらず、判定帰納言語は加算帰納言語の真部分クラスである。
証明.$\Sigma$上の万能TM$\mathcal{U}$に対し、$\mathcal{L}(\mathcal{U})$は加算帰納言語である。
線形有界オートマトンと単調文法
 線形有界オートマトン(Linear Bounded Automaton, LBA)$M=(Q,\Sigma,\Gamma,\delta,q_0,F)$は、TMの一種で、テープの延長ができないものをいう。
線形有界オートマトン(Linear Bounded Automaton, LBA)$M=(Q,\Sigma,\Gamma,\delta,q_0,F)$は、TMの一種で、テープの延長ができないものをいう。形式的には、$(q,X,Y,D,p)\in\delta$ の動作に次の制限を課す。ID $\alpha qX\beta$ に対し $\begin{cases} \alpha{=}\varepsilon & \drarrow qX\beta \vdash Yp\beta & 即ち D{=}R\\ X\beta{=}□ & \drarrow \alpha q□ \vdash \alpha' pZ□ & 即ち Y{=}{□} \wedge D{=}L\wedge \alpha{=}\alpha'Z \end{cases}$
LBAは、初期IDでヘッドがテープ左端にあるので、そこに印をつけておけば、後の動作で(必要なら)左端を検出できる。一方、テープ右端は、実際に右に動いて空白セルを見出すまで不明なので、その動作は許すがそこに非空白記号を書いてテープを延長することは禁じている。LBAでは、ID $\alpha q□$ を $\alpha q$ と表すことにすれば、動作$\vdash$の左右でIDの長さが変わらず、$q_0\vect{w}\VDASH{}{*} \alpha q\beta \drarrow |\vect{w}|=|\alpha\beta|$ が成立つ。LBAはTM同様、多重トラックや多テープ化が可能で、入力テープの他にその定数倍の作業領域を利用できるため、線形有界と呼ばれる。
例.$0^n1^n$を受理する(決定性)LBA(右上図)は、例えば以下のように動作する。
$q_00011\vdash Xq_1011\vdash X0q_111\vdash Xq_20Y1\vdash q_2X0Y1\vdash Xq_00Y1\vdash XXq_1Y1\vdash XXYq_11 \\ \vdash XXq_2YY\vdash Xq_2XYY\vdash XXq_0YY\vdash XXYq_3Y\vdash XXYYq_3\vdash XXYq_4Y(受理)$
文法$G=(\Gamma,\Sigma,P,S)$は規則が$\alpha\to\beta,\ \alpha{\in}(\Sigma{\cup} \Gamma)^*{-}\Sigma^*,\ \beta{\in}(\Sigma{\cup}\Gamma)^*,\ |\alpha|{\leqq}|\beta|$の時単調文法という。 ただし規則の右辺に現れない開始記号$S$に限り$S\to\varepsilon$を許す
定理.次の2条件は同値で、それを満たす言語を文脈依存言語という。
- 単調文法で生成される
- (非決定性)LBAで認識される
- LBAの時点表示のテープ長は入力$w$の長さであり
- 単調文法で$w$の導出途中に現れる記号列は$w$の長さ以下である
文脈依存言語の性質
定理.文脈依存言語は、集合演算(和、積、差、補集合)、反転、準同型写像のもとで閉じている。証明.補集合で閉じていることのみ証明の概要を紹介する。
LBA $M=(Q,\Sigma,\Gamma,\delta,q_0,F)$と入力$\vect{w}\in\Sigma^n$に対し、$\mathcal{I}:=\bigcup_{k=0}^n \Gamma^{k}Q\Gamma^{n-k}$、$\mathcal{I}_F:=\bigcup_{k=0}^n \Gamma^{k}F\Gamma^{n-k}$、$\mathcal{I}_*:=\{\alpha q\beta \mid q_0\vect{w}\VDASH{}{*}\alpha q\beta\}$とおく。$\mathcal{L}(M)^\complement=\mathcal{L}(M^\complement)$となるLBA $M^\complement$は、入力$\vect{w}$に対しまず$|\mathcal{I}_*|$を計算し、次に各ID $I\in\mathcal{I}$を辞書式順序で構成し、$M$を(非決定的に)模倣して$I\in I_*$か否かのチェックを始める。
- $I\in \mathcal{I}_*\cap\mathcal{I}_F$ならば$M^\complement$は$\vect{w}$を受理せず停止する。
- $I \in \mathcal{I}_*-\mathcal{I}_F$ならば、カウンタを1ふやして、次のID$I$を試す。
- $I \not\in \mathcal{I}_*$と判断したら、カウンタをふやさず、次のID$I$を試す。
さて、入力$\vect{w}$にたいし、$M^\complement$が$|\mathcal{I}_*|$をどのように求めるかを示すために$\mathcal{I}_0:=\{q_0\vect{w}\},\ \mathcal{I}_{j+1}:=\{I'\mid I\VDASH{}{?}I',I\in \mathcal{I}_j\},\ j=0,1,\cdots$とおく。ここで、$I\VDASH{}{?}I'\darrow{\rightarrow}{\leftarrow} I=I' \vee I\vdash I'$ で、$\mathcal{I}_j$は初期IDから$j$ステップ以下で到達可能なIDの集合である。$M^\complement$は$|\mathcal{I}_j|$の値を使って$I'\in \mathcal{I}_{j+1}$か否かを上と同様のアイディアで判定する以下のルーチンを利用する。ルーチンは各ID $I\in\mathcal{I}$を辞書式順序で構成し、$M$を(非決定的に)模倣して$I\in I_j$か否かのチェックを始める。
- $I\in \mathcal{I}_j\wedge I\VDASH{}{?}I'$ならば、$I' \in \mathcal{I}_{j+1}$とし、このルーチンを終わる。
- $I \in \mathcal{I}_j\wedge I\not\VDASH{}{?}I'$ならば、カウンタを1ふやし、次のID$I$を試す。
- $I \not\in \mathcal{I}_j$と判断したら、カウンタをふやさず、次のID$I$を試す。
$M^\complement$はこのルーチンを各$I\in\mathcal{I}$に辞書式順序で適用し、$|\mathcal{I}_j|$から$|\mathcal{I}_{j+1}|$を求める。$|\mathcal{I}_0|=1$からこれを繰返せば、いつかは、$|\mathcal{I}_j|=|\mathcal{I}_{j+1}|=|\mathcal{I}_*|$が求まる。
また、$M^\complement$が利用するデータ、$I\in\mathcal{I}$や数値$|\mathcal{I}_*|$等は長さ$|\vect{w}|$のテープに収めて表現できるので$M^\complement$はLBAである。
文脈依存言語が補集合演算で閉じていることは、1988年に示されたが、(非決定性)LBAが決定性LBAより真に能力が高いか否かは未解決問題である。
定理.文脈異存言語は判定帰納言語である。