この章の目標
この講義で扱う対象は文字列の集合です。人は、母語に特有な文字の列(文)を、読み・書き・聞き・話し ます。我々は通常、日本語文法に則した文字列(文)を作り出し(書き・話し)、それを認識(読み・聞き)します。言い換えると、日本語は、日本語文法に即して生成された文字列の集合であり、人が日本語だと認識する文字列の集合です。プログラミング言語では、その言語の文法に即して書かれた文字列(プログラム)をコンピュータが認識して実行します。ただし、この意味で日本語(等の自然言語)を厳密に定めることは至難の業で、この講義のテーマではありません。この講義の主要なテーマ(興味)は、文字列の集合を定義する生成機構(文法)と認識機構(オートマトン:自動機械)の対応関係です。この分野は、計算機科学の基礎を成し、テキスト処理やコンパイラ、計算可能性や計算量理論など広範な応用範囲を持つともに、数理論理学とも密接な関連を持ちます。この章では。この講義の基本的な用語・概念を紹介し、内容を概観します。
基本的な用語・概念
・字母(アルファベット)
・文字列
・言語
・文法
・オートマトン
文字列とその演算
文字(や記号)の有限集合を字母(アルファベット)といい、通常$Σ$(や$Γ$)で表す。$Σ$の文字を(重複を許して)$n$個ならべたものを$Σ$上の長さ$n$の文字列といい、その集合を$\color{blue}{\Sigma^n}$と表す。特に長さ$0$の文字列を空列といい通常$\color{blue}\varepsilon$で表す。よって、$\Sigma^0=\{\varepsilon\},\ \Sigma^1=\Sigma$。$\color{blue}{\Sigma^*}:=\Sigma^0\cup\Sigma^1\cup\Sigma^2\cup\cdots$で$\Sigma$上の文字列の全体を表す。文字列$\vect{w}$の長さを$\color{blue}{|\vect{w}|}$で表す。例.$Σ=\{a,b\}$とする。
$\Sigma^3=\{a,b\}^3=\{aaa,aab,aba,abb,baa,bab,bba,bbb\}$
$\Sigma^*=\{a,b\}^*=\{\varepsilon, a, b, aa, ab, ba, bb, aaa, \dots\}$
$\vect{w}=abba\Rightarrow |\vect{w}|=|abba|=4$
文字列の演算
文字列の基本的な(2項)演算はそれらをつなげて1つの文字列にすることで、$\ \cdot\ $で表し連接という。通常(誤解が生じなければ)$\ \cdot\ $を省略する。文字列$\vect{w}$を$n$回つなげた文字列を$\vect{w}^n$で表す。
例.$a\cdot ba=a(ba)=aba,\ ba\cdot a=(ba)a=baa,\ \varepsilon\cdot \vect{w}=\vect{w}\cdot \varepsilon=\vect{w}$
$a^4=aaaa,\ (ab)^3=ababab,\ \vect{w}^0=\varepsilon$
文字列$\vect{w}$の文字の順番を反転した文字列を$\vect{w}^R$と表す。
例.$(abb)^R=bba$、一般に$(a_1a_2\cdots a_n)^R=a_n\cdots a_2a_1$
パズル
- $\Sigma^n,\ n{=}0,1,\dots$ を$n$に関して帰納的に定義せよ
- $\vect{v}\vect{w}=\vect{w}\vect{v}$ となる必要十分条件は文字列 $\vect{v}$ と $\vect{w}$ がともにある文字列 $\vect{x}$ のベキ($\vect{v}=\vect{x}^n,\ \vect{w}=\vect{x}^m$)であることを示せ
- $\{x\mid x\ は20以下の素数\}=\{2,3,5,7,11,13,17,19\}\subseteq\{1,2,3,5,7,9\}^*$ は正しいか。
準同型写像
文字列の写像 $h:\Sigma^*\to \Gamma^*$ で $h(\vect{v}\vect{w})=h(\vect{v})h(\vect{w})$ を満たす(連接を保存する)ものを準同型写像といい、$h:\Sigma\to \Gamma^*$ から一意に定まる(拡張できる)。
例.$h(a)=00,\ h(\color{red}{b})=\color{red}{101}$ なら $h(a\color{red}{b}a)=00\color{red}{101}00。$
特に$h$が単射である($\vect{v}=\vect{w} \darrow{\rightarrow}{\leftarrow} h(\vect{v})=h(\vect{w})$)とき、$h$を符号化と呼び、$h(\Sigma):=\{h(a)\mid a\in\Sigma\}$を符号と呼ぶ。
パズル
コラム 将棋の千日手(指し直し)の規定が1983年に、「同一手順を$3$回繰り返した時」から、「同一局面が$4$回出現した時」に変わった。
理由は、準同型写像$h(0){:=}01,h(1){:=}10$に対し、$\vect{w}_n{:=}h^n(0)$と定めると$\vect{w}_0=0,\ \vect{w}_1=01,\ \vect{w}_2=0110,\ \vect{w}_3=01101001,\cdots$
は同一文字列の$3$回の繰り返し $\vect{x}^3$ を部分文字列として含まないため、同一手順を3回繰返すことなく無限に指し続けることができることによる。
略証.語$\vect{w}=a_0a_1\cdots a_{|\vect{w}|-1}$に対し$\vect{w}[i]=\vect{w}[i,1]:=a_i,$ $\vect{w}[i,t]:=a_ia_{i+1}\cdots a_{i+t-1},$ $B(\vect{w}):=\{\vect{w}[i,2]\mid 0{\le}i{\lt}|\vect{w}|\}$とおく。$h(\vect{w}_{n-1}[i])=\vect{w}_n[2i,2]{\in}\{01,10\}$より
$t=2u$ なら3.より、$i=2k$ とできて$\vect{w}_{n-1}[k,2u{+}1]=\vect{w}_{n-1}[k,u]^2\vect{w}_{n-1}[k]$。よって $t$ は奇数としてよく、$B(\vect{w}_n[i,t])\subseteq\{01,10\}$なら$\vect{w}_n[i{+}t{-}1]=\vect{w}_n[i{+}t]$。よって、$00$又は$11$が$\vect{w}_k[i,2t+1]$に2回、$t$ ずれた位置に現れ、1.に矛盾する。
さらに、$\vect{w}_n$は$\vect{w}_{n-1}$の延長になっているので、$\vect{x}^3$(厳密には$\vect{x}^2\cdot\vect{x}[0]$)を出現させずにいくらでも$0,1$列を延長できることが示せた。
文字列の写像 $h:\Sigma^*\to \Gamma^*$ で $h(\vect{v}\vect{w})=h(\vect{v})h(\vect{w})$ を満たす(連接を保存する)ものを準同型写像といい、$h:\Sigma\to \Gamma^*$ から一意に定まる(拡張できる)。
例.$h(a)=00,\ h(\color{red}{b})=\color{red}{101}$ なら $h(a\color{red}{b}a)=00\color{red}{101}00。$
特に$h$が単射である($\vect{v}=\vect{w} \darrow{\rightarrow}{\leftarrow} h(\vect{v})=h(\vect{w})$)とき、$h$を符号化と呼び、$h(\Sigma):=\{h(a)\mid a\in\Sigma\}$を符号と呼ぶ。
パズル
- $h:\Sigma^*\to \Gamma^*$ が準同型写像ならば $h(\varepsilon)=\varepsilon$ であることを示せ
- $h(a)=1,\ h(b)=01,\ h(c)=00$ のとき $h(\vect{w})=011001$ となる $\vect{w}$ を求めよ。また $h$ が符号化であることを示せ。
コラム 将棋の千日手(指し直し)の規定が1983年に、「同一手順を$3$回繰り返した時」から、「同一局面が$4$回出現した時」に変わった。
理由は、準同型写像$h(0){:=}01,h(1){:=}10$に対し、$\vect{w}_n{:=}h^n(0)$と定めると
略証.語$\vect{w}=a_0a_1\cdots a_{|\vect{w}|-1}$に対し$\vect{w}[i]=\vect{w}[i,1]:=a_i,$ $\vect{w}[i,t]:=a_ia_{i+1}\cdots a_{i+t-1},$ $B(\vect{w}):=\{\vect{w}[i,2]\mid 0{\le}i{\lt}|\vect{w}|\}$とおく。$h(\vect{w}_{n-1}[i])=\vect{w}_n[2i,2]{\in}\{01,10\}$より
- $\vect{w}_n[j,2]\in\{00,11\} \drarrow j$は奇数
- $\vect{w}_n[2i]=\vect{w}_n[2j] \darrow{\rightarrow}{\leftarrow}\vect{w}_n[2i{+}1]=\vect{w}_n[2j{+}1]$
- $\vect{w}_n[2i,2t{-}1]=\vect{w}_n[2j,2t{-}1],\ \vect{w}_n[2i{+}1,2t{-}1]=\vect{w}_n[2j{+}1,2t{-}1],\ $$\vect{w}_{n-1}[i,t]=\vect{w}_{n-1}[j,t]$ はいずれも$\vect{w}_n[2i,2t]=\vect{w}_n[2j,2t]$と同値($t{\gt}0$)
$t=2u$ なら3.より、$i=2k$ とできて$\vect{w}_{n-1}[k,2u{+}1]=\vect{w}_{n-1}[k,u]^2\vect{w}_{n-1}[k]$。よって $t$ は奇数としてよく、$B(\vect{w}_n[i,t])\subseteq\{01,10\}$なら$\vect{w}_n[i{+}t{-}1]=\vect{w}_n[i{+}t]$。よって、$00$又は$11$が$\vect{w}_k[i,2t+1]$に2回、$t$ ずれた位置に現れ、1.に矛盾する。
さらに、$\vect{w}_n$は$\vect{w}_{n-1}$の延長になっているので、$\vect{x}^3$(厳密には$\vect{x}^2\cdot\vect{x}[0]$)を出現させずにいくらでも$0,1$列を延長できることが示せた。
言語とその演算
字母$\Sigma$上の言語とは、$\Sigma^*$の部分集合(つまり文字列の集合)をいう。言語$A,\ B$に対する基本演算や記法には次ようなものがある。- 集合演算:$和:\cup,\ 積:\cap,\ 差:-,\ 補集合:^\complement$
- 連接 $A・B$$:=\{\vect{vw}\mid \vect{v}\in A,\ \vect{w}\in B\}$
$A$の文字列に$B$の文字列を繋げた文字列全体。通常$\ \dot\ $を省略する。 - ベキ $A^n$$:=\{\vect{w}_1\vect{w}_2\cdots \vect{w}_n\mid \vect{w}_1,\vect{w}_2,\dots,\vect{w}_n\in A\}$
$A$の文字列を$n$個繋げた文字列全体
$A^?$$:=A^0\cup A^1=\{\varepsilon\}\cup A$ - クリーネ閉包 $A^*$$:=A^0\cup A^1\cup A^2\cup\cdots$
$A$の文字列を0個以上つなげた文字列全体
正閉包 $A^+$$:=AA^*=A^1\cup A^2\cup\cdots$
- 反転 $A^R$$:=\{\vect{w}^R\mid\vect{w}\in A\}$
- 準同型写像 $h(A)$$:=\{h(\vect{w})\mid\vect{w}\in A\}$
パズル.
-
$A=\{a,ab\}$とする。$A^?A,\ AA^R,\ A^+$を求めよ
- $\{a\}\{a,b\}^*\{a\}\cup\{b\}\{a,b\}^*\{b\}$ はどのような言語か、説明せよ
- 準同型写像$h:\Sigma^*\to\Gamma^*,\ A,B\subseteq\Sigma^*$に対し、$h(A\cup B)=h(A)\cup h(B),\ h(AB)=h(A)h(B),\ h(A^*)=h(A)^*$を示せ
- $(A{\cup}B)^R=A^R{\cup}B^R,\ (AB)^R=B^RA^R,\ (A^*)^R=(A^R)^*$を示せ
注.計算機科学では、$0$回以上の繰り返しを$\;^*$で、$1$回以上の繰り返しを$\;^+$で、$0$または$1$回の繰り返しを$\;^?$で表すことが多い。$\Sigma^*$は$\Sigma$の文字を0回以上繰り返した文字列の全体である。
文法とは
言語は、一般に無限集合だから、外延的な(並べあげる)記述(定義)はできない。内包的に記述(定義)する仕組みとしては、前節で紹介した演算や言葉による表現の他に、言語を生成する仕組みとしての文法と、言語を認識する仕組みとしてのオートマトンがある。まず、文法について考えてゆこう。チョムスキーは、人が幼児期に母語を驚くほど短期間に獲得するのは、普遍文法による言語生成の機能を生得的に備えているからであり、すべての言語に共通の文法構造があると考えた。ここで、 普遍文法(句構造文法)は、書換え規則の集まりと開始記号から成る。
例として、日本語のごく一部を生成する文法を考えてみよう。
/文/→/主語//述部/
/述部/→/述語/|/目的語//述部/
/主語/→ 私は|君は|・・・
/目的語/→車を|愛を|彼に|・・・
車を/述語/→車を売る|車を買う・・・
愛を/述語/→愛を感じる・・・
- 文法中の記号は終端記号(文字)か非終端記号(文法要素)の2種類あり、例では/と/で挟まれたものが非終端記号である。
- 規則は 左辺→右辺の形をしている。例では左辺が等しい規則を1つにまとめ、右辺を | で区切って表している。
- 非終端記号の1つが開始記号として指定される。(例では/文/)
- 規則の左辺はすくなとも1つ非終端記号を含む
文法の規則$\alpha\to\beta$による導出とは、非終端・終端記号列$\gamma\alpha\delta$中の規則左辺$\alpha$を規則右辺$\beta$で置き換える操作をいい、$\gamma\alpha\delta\Rightarrow\gamma\beta\delta$と書く。導出$\Rightarrow$の0回以上の繰り返しを$\overset{*}{\Rightarrow}$で表す。即ち、$\gamma_0\Rightarrow\gamma_1\Rightarrow\cdots\Rightarrow\gamma_n,\ n\ge 0$ のとき $\gamma_0\overset{*}{\Rightarrow}\gamma_n$と表す。
| 導出 | 適用規則 |
|
/文/ ⇒/主語//述部/ ⇒/主語//目的語//述部/ ⇒私は/目的語//述部/ ⇒私は彼に/述部/ ⇒私は彼に/目的語//述部/ ⇒私は彼に/目的語//述語/ ⇒私は彼に車を/述語/ ⇒私は彼に車を売る |
/文/→/主語//述部/ /述部/→/目的語//述部/ /主語/→ 私は /目的語/→彼に /述部/→/目的語//述部/ /述部/→/述語/ /目的語/→車を 車を/述語/→車を売る |
| /文/$\overset{*}{\Rightarrow}$私は彼に車を売る |
文法が生成する文字列とは、開始記号から導出される終端文字列をいい、文法が生成する言語とは文法が生成する文字列の集合をいう。2つの文法が等しいというのは、それらが生成する言語が等しいときである。
パズル.上に倣って、前頁の文法が生成する文を例示せよ。
文法の階層
文法は規則の形によって次のようにクラス分けされる。ここで、$\Gamma$は非終端字母(文法要素)、$\Sigma$は終端字母(文字)を表す。定義より、正則文法$\Rightarrow$文脈自由文法$\Rightarrow$単調文法$\Rightarrow$句構造文法、であり、各々のクラスに属する典型的な文法をそれが生成する言語を示した。| 文法クラス | 規則の形 |
| 文法の例 開始記号$S$ | 生成する言語 |
| 正則(正規)文法 | $A\to \vect{w}B$($A\in\Gamma,\ \vect{w}\in\Sigma^*,\ B\in\Gamma^?$) |
| $S\to 0S|0B$ $B\to 1B|1$ |
$\{0^n1^m|n,m\in\mathbb{N}_+\}$ |
| 文脈自由文法 | $A\to \beta$($A\in\Gamma,\ \beta\in (\Sigma\dot{\cup}\Gamma)^*$) |
| $S\to 0S1|01$ | $\{0^n1^n|n\in\mathbb{N}_+\}$ |
| 単調文法 | $\alpha\to\beta$($\alpha\in(\Sigma^*\Gamma)^+\Sigma^*,\ \beta\in (\Sigma\dot{\cup}\Gamma)^*,\ |\alpha|\leq|\beta|$注) |
| $S\to 012|0SB2$ $2B\to B2$ $1B\to 11$ |
$\{0^n1^n2^n|n\in\mathbb{N}_+\}$ |
| 句構造文法(制限なし) | $\alpha\to\beta$($\alpha\in(\Sigma^*\Gamma)^+\Sigma^*,\ \beta\in (\Sigma\dot{\cup}\Gamma)^*$) |
パズル.単調文法の上の定義では空列を生成できないことを示せ。
注.このため単調文法は規則の右辺に現れない開始記号$S$に限り$S\to\varepsilon$を許す
オートマトンとその階層
この節では、言語を認識・受理する(与えれた文字列がその言語に属すか否か判定する)仕組み・機械としてのオートマトンについて概観する(厳密な定義や議論は後の章に譲る)。オートマトンは、有限制御部と入力が記されたテープを持ち、テープ(ヘッド)を移動させてセル中の文字を読み(書きし)ながら、有限制御部の状態を遷移させてゆく。オートマトンはその開始状態から出発し受理状態で停止するとき、そのテープ上に最初に書かれていた文字列を受理するという。
オートマトンが受理する文字列の集合を、オートマトンが認識(受理)する言語という。2つのオートマトンが等しいというのはそれらが認識する言語が等しい時である。
パズル.automaton(オートマトン)の本来の意味は何か
| 有限オートマトン |  |
| テープヘッドは読込のみで、右方向にしか動かない |
例.上の有限制御部を持つ有限オートマトンは ${\rhd}\transition{q_0}{0}\transition{q_2}{1}\transition{q_1}{0}\transition{q_1}{1}\ \cdots$ のように動作し、テープを読み終わって停止したときに状態が◎で示された受理状態($\dcircled{q_1}$)であれば、テープ上の文字列を受理(認識)する。
詳細は後の章に譲るが、有限オートマトンに機能を付け加えて次のようなタイプのオートマトンを考えると、文法との密接な関連が成立つ。
パズル.スタックがLIFO(Last In First Out)であるとはどういう意味か?
| プッシュダウンオートマトン | 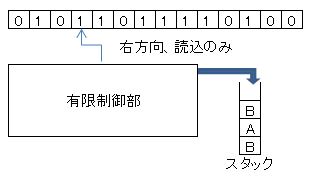 |
|
有限オートマトン+スタック 【一方向から記号の追加・読出し(取出し)ができる補助記憶装置】 |
|
| 線形有界オートマトン | 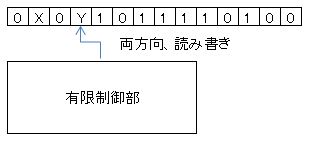 |
| 入力テープが同時に作業テープの役割を果たし、テープヘッドが行きつ戻りつしながら読み書きできる | |
| チューリングマシーン | 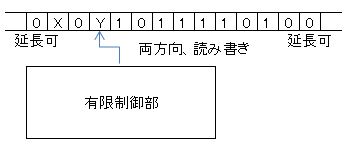 |
| さらにテープを必要なら両方向にいくらでも延長できる |
パズル.スタックがLIFO(Last In First Out)であるとはどういう意味か?
非決定性オートマトン
オートマトンは、有限制御部の状態とテープやスタックのヘッドが読込む文字から、その動作が一意に定まることが望ましく、決定性オートマトンと呼ばれる。それに対し、状態と読込文字に対し、複数の動作が定義されてもよいとするオートマトンを非決定性オートマトンという。決定性オートマトンでは、入力(文字列)に対する動作列は一意で、機械が受理するか否かは停止した時の状態で決まる。一方、非決定性オートマトンでは、複数の可能な動作列中に、受理状態で停止するものがあれば入力を受理する。言い換えると機械は受理に至る動作列(があればそれ)を適切に選ぶという、非常に都合のよい特殊能力を仮定している。非決定性オートマトンは設計はしやすいが、実装には決定性(への変換)が必要である。

|
以下に入力列の受理・非受理と、入力を読み終わって停止した時の受理状態・非受理状態の有無との関係を示す。
| 入力(ラベル)列 | 停止時の状態 | 受理 |
| 1001 | 受理q2・非受理q0 | 受理 |
| 1010 | 受理無・非受理q0,q1 | 非受理 |
文法とオートマトンの対応関係と言語階層
詳細な議論は後の章で行うことになるが、文法の生成能力とオートマトンの認識能力の階層関係は以下のようにまとめることができる。- 決定性有限オートマトンと非決定性有限オートマトンの認識能力は、ともに正則文法の生成能力と等しく、それらが認識・生成する言語を正則言語という。
- 決定性プッシュダウンオートマトンが認識する言語を決定性文脈自由言語という。
- 非決定性プッシュダウンオートマトンの認識能力と文脈自由文法の生成能力は等しく、それらが認識・生成する言語を文脈自由言語という。
- 決定性線形有界オートマトンが認識する言語を決定性文脈依存言語という。
- 非決定性線形有界オートマトンの認識能力と単調文法の生成能力は等しくそれらが認識・生成する言語を文脈依存言語という。
- 決定性チューリング機械と非決定性チューリング機械の認識能力は句構造(無制限)文法の生成能力と等しく、それらが認識・生成する言語を帰納的可算言語という。
コラム.文脈依存言語という術語は、このクラスが最初、文脈依存文法という、規則が$\alpha A\beta\to\alpha\gamma\beta,\ |\gamma|\geq 1$の形をしていて、$A$の$\alpha$への書き換えが$A$の前後の文脈に依存する文法で生成される言語として定義されたことに由来する。また、その意味で規則が単に$A\to \gamma$という形をしている文法を文脈自由文法と呼んでいる。
帰納的可算言語という術語は、このクラスの言語では、属する文字列の列挙(のみ)が可能であるという事実に由来する。
前ページで定義されたクラスは、決定性文脈依存言語のクラスが文脈依存言語のクラスに真に含まれるか否かが未解決なことを除けばいずれもその下のクラスに真に含まれる。
正則言語$\subset$決定性文脈自由言語$\subset$文脈自由言語$\subset$
決定性文脈依存言語$\subseteq$文脈依存言語$\subset$帰納的加算言語
以下に各クラスに属し上の行のクラスに属さない典型的な言語を例示する。
コラム.前章の濃度の関する結果より、字母$\Gamma,\Sigma$に対し、$|\Gamma^*|\lt |\vect{2}^{\Sigma^*}|$である。即ち、言語$L\subseteq \Sigma^*$のうち、文法やオートマトン、言語演算、自然言語等何らかの仕組みで記述($\in\Gamma^*$)できるものは実はごくわずかである。
決定性文脈依存言語$\subseteq$文脈依存言語$\subset$帰納的加算言語
以下に各クラスに属し上の行のクラスに属さない典型的な言語を例示する。
| 言語クラス | 下の階層に属さない言語例 |
| 正則言語 | $\{0^m1^n|m,n\in\mathbb{N}_+\}$ |
| 決定性文脈自由言語 | $\{0^n1^n|n\in\mathbb{N}_+\},\ \{\vect{w}c\vect{w}^R|w\in\{0,1\}^+\}$ |
| 文脈自由言語 | $\{\vect{w}\vect{w}^R|\vect{w}\in\{0,1\}^+\}$ |
| 決定性文脈依存言語 | $\{0^n1^n2^n|n\in\mathbb{N}_+\},\ \{\vect{w}\vect{w}|\vect{w}\in\{0,1\}^+\}$ |
| 文脈依存言語 | 未解決 |
| 帰納的可算言語 | $\{(P,\vect{w})|プログラムPは入力\vect{w}で停止する\}$ |
| 任意の言語 | $\{(P,\vect{w})|プログラムPは入力\vect{w}で停止しない\}$ |
コラム.前章の濃度の関する結果より、字母$\Gamma,\Sigma$に対し、$|\Gamma^*|\lt |\vect{2}^{\Sigma^*}|$である。即ち、言語$L\subseteq \Sigma^*$のうち、文法やオートマトン、言語演算、自然言語等何らかの仕組みで記述($\in\Gamma^*$)できるものは実はごくわずかである。
JFLAPの利用
 この講義では図の作成や実例の提示などにJFLAPを利用している。javaの実行環境をインストールした上で、JFLAPのサイトから JFLAP7.1.jar をダウンロードしよう。ダウンロードしたファイルがダブルクリックで実行されないときは、バッチファイルを同じフォルダにダウンロードしダブルクリックすれば、実行できる。(右図のようにコマンドプロンプトから実行される)
この講義では図の作成や実例の提示などにJFLAPを利用している。javaの実行環境をインストールした上で、JFLAPのサイトから JFLAP7.1.jar をダウンロードしよう。ダウンロードしたファイルがダブルクリックで実行されないときは、バッチファイルを同じフォルダにダウンロードしダブルクリックすれば、実行できる。(右図のようにコマンドプロンプトから実行される)使い方はチュートリアルサイトが参考になる。