前処理とは
あらかじめデータに前処理を施すことによって、処理本体(時間)を効率化する注意.処理本体が重くなければ、前処理の手間が負担になることがある
例.多項式の反復計算:ホーナー法
$f(x)=5x^3+2x^2+6x+7$の計算:掛け算$3+2+1=6$回、足し算$3$回
$f(x)=((5x+2)x+6)x+7$の計算:掛け算$3$回、足し算$3$回
$\displaystyle f(x)=a_nx^n+a_{n-1}x^{n-1}+\cdots+a_1x+a_0$の計算
掛け算$\displaystyle \sum_{k=0}^n k=\frac{n(n+1)}{2}$回、足し算$n$回
$f(x)=(\cdots((a_nx+a_{n-1})x+a_{n-2})x+\cdots+a_1)x+a_0$の計算
掛け算$n$回、足し算$n$回
$y\leftarrow a_n$
$i= n-1, n-2, \cdots, 0$ に対し $y \leftarrow y\times x+a_i$
テキスト探索
指定された文(テキスト)中から、指定された語の位置を求める。インターネット検索の基本機能
素朴な方法(文や語は第$0$文字から始まる)
$i \leftarrow 0;\ j \leftarrow 0;$
①語の第$j$文字を文の第$i$文字と照合する
一致すれば$i,j$を共に1増やす
語の最後にきたら成功。$i-j$を返して終了
しなければ再照合:$i\leftarrow i-j+1,\ j \leftarrow 0;$とし①へ
パズル.最悪の振舞をする次の例における文字の比較回数求めよ
文:$aaaaaaaaaaaaaaaaaaaaaaab=a^{24}b$
語:$aaaab=a^4b$
参考
KMP法:Knuth, Morris, Pratt
素朴な方法を改善KMP法(文や語は第$0$文字から始まる)
$i \leftarrow 0;\ j \leftarrow 0;$
①語の第$j$文字を文の第$i$文字と比較する
一致すれば$i,j$を共に1増やす
語の最後にきたら成功。$i-j$を返して終了
しなければ再照合:($j=0$なら$i$を1増やし)
$j \leftarrow f(j);$とし①へ
アイディア:文の第$i$文字と語の第$j$文字で不一致が起きた
⇒文の第$(i-j)~(i-1)$文字=語の第$0~(j-1)$文字
⇒その部分の再照合結果は、語の情報だけから分かる
⇒語中の照合再開位置$f(j)$を前もって(文と無関係に)計算できる(筈!)
BM法:Boyer, Moorによる
簡易BM法(語の最終文字位置$=$長さ$-1$を$n$とする)$i \leftarrow n;\ j \leftarrow n;$
①語の第$j$文字を文の第$i$文字と比較する
一致すれば$i,j$を共に1減らす
語の先頭にきたら成功。$i$を返して終了
しなければ再照合:
$i \leftarrow パターン右端+g(文の第i文字);$
$j\leftarrow n;$とし①へ
関数$g(c)$の値は語中の文字$c$の最右出現位置から求めることができる
本来のBM法は、再照合位置を求める二つの表(関数)を利用
・$g(文字)=語長-文字の最右出現位置$
・KMP法のアイディア
正規(正則)表現とは
正規表現は、文字列パターンの記述であり文字列$w$は正規表現$\alpha$に合致するという。正規表現による検索・置換機能が実装されているプログラミング言語も多い
∵)正規表現と後述の有限オートマトン(有限状態機械)は識別能力が同等
基本の表現
| 記法 | 説明 |
| 文字列 | 文字列や空列はそのまま文字列(空列)と合致。 |
| 連接 | 正規表現を続けて書けば、それらを続けた文字列と合致 |
| | | 和(または)。どちらかのパターンと合致すれば合致。 |
| * | 直前の文字(文字列)の0回以上の繰り返しと合致 |
例.(0|1)*01 は
0 または[|] 1 を 0回以上つなげた[*] 後に 01 をつなげた文字列
即ち、01 で終わる 0,1 の文字列を表す。
さらに次節で述べるような多くの便宜的記法がある。
正規表現の記法
繰返し| 記法 | 説明 | 使用例 |
| + | 1回以上の繰り返し | 12+ → 12、122、・・・ と合致 12+=122* |
| ? | 0,1回の繰り返し | 12? → 1、12 と合致 12?=1|12 |
| {n} | n回繰り返し | (ab){3} → abababに合致 |
| {n, } | n回以上繰り返し | a{3,} →aaa、aaaa、…に合致 |
| {m,n} | m~n回繰り返し | a{3,5} →aaa、aaaa、aaaaaに合致 |
正規表現の記法
文字の集合:1文字指定する| 記法 | 説明 | 使用例 |
| . | 改行文字を除く任意の1文字 | windows.. windowsの後に2文字続く文字列と合致 |
| [ ] | [ ] 内に並べた文字のどれか | [ab]=a|b |
| - | 文字の区間。[ ] 内で用いる | [a-z]=a|b|・・・|z 小文字アルファベット全て [0-9]=0|1|・・・|9 全角の数字 [0-9A-Z] 大文字のアルファベットか数字 |
| ^ | 否定。[ ] 内で用いる | [^a-z] 小文字のアルファベット以外全て |
合致する文字列は、通常はパターンに適合する最長の文字列(最長合致)であるが、"?"を付加すれば最短合致となる。
12+ →1222222222 に対し10桁目の1222222222までと合致
12+? →1222222222 に対し2桁目の12までと合致
正規表現の記法
特殊な意味を持つ表現| 記法 | 説明 | 使用例 |
| ^ | 行頭 | ^abc →行頭にある abc と合致 |
| $ | 行末 | abc$ →行末にある abc と合致 |
|
|
正規表現による英文分析
正規表現による検索では grep が有名だが、ここでは英文の分析に利用する例を紹介しよう。これによって、文書・文献の特徴を数量的に抽出し、著者の異同や時代の推定、思想と文体との関係等を分析することも可能になる。その意味で、正規表現検索は文体の処理・解析のための重要なツールになっている。実験.秋田大学のSCORP検索(http://www.mis.med.akita-u.ac.jp/%7Etaka/FreeSCORP/)
- Search Word欄に色々な正規表現を入れて試してみよう。
- 適当な動詞(過去、過去分詞、三単元を含む)の出現数を調べてみよう。
パズル.正規表現 \s(for|in|on|to|with)\s[a-z]+ing\s(for|in|of|on|to|with)\s は何を意味するか考えよ。
正規表現による検索と置換
$\$n$:正規表現の$n$番目の括弧対で括られた部分に合致した文字列右のフレームで検索文字列や置換文字列を指定して[検索]、[置換]を押すと結果が下の欄に表示される(Java Scriptで実装)
パズル.1~5の正規表現を求め検索・置換せよ。
- 3桁の数字
- 3000未満の非負整数
- aで始まりaで終わる6文字以下の英小文字列
- 全角数字0~9で始まり句点。で終わる行
- 英字の姓と名を入れ替よ
有限オートマトン(FA)
 $\Sigma$上の有限オートマトン(FA)$M$
$\Sigma$上の有限オートマトン(FA)$M$
状態(○)と遷移(ラベル付き矢印$\labelarrow{a},\ a\in\Sigma^?$)
入力$a$(空列$\varepsilon$の場合は入力なし)による状態遷移
開始状態(▷○、1つ)と、受理状態(◎、複数可)
開始状態から受理状態への遷移列(路)の入力(ラベル)列を受理
受理入力列の集合を認識(受理)。
時点表示:(状態,未読文字列)
$(q_0,1001)\vdash(q_0,001)\vdash(q_0,01)\vdash(q_1,1)\vdash(q_2,\varepsilon)⇒(q_0,1001)\overset{*}{\vdash}(q_2,\varepsilon)$:受理
$\transition{q_0}{1}\transition{q_0}{0}\transition{q_0}{0}\transition{q_1}{1}\circled{q_2}$を$\transition{q_0}{1001}\circled{q_2}$と書けば
$(q,w)\overset{*}{\vdash}(p,\varepsilon) \Leftrightarrow\transition{q}{w}\circled{p}$。
FA$M$が認識する言語:$L(M)=${$w$|(▷○,$w$)$\overset{*}{\vdash}$(◎,$\varepsilon$)}={$w$|▷○$\labelarrow{w}$◎}
パズル.右上図のFAについて
①$1001$に対する可能な動作をすべて調べよ
②どのよな文字列を受理するか
農夫パズル
 オオカミ(W)とヤギ(G)を連れキャベツの籠(C)を持った農夫(F)が小舟で川を渡りたい。
オオカミ(W)とヤギ(G)を連れキャベツの籠(C)を持った農夫(F)が小舟で川を渡りたい。
- 小舟には農夫の他一匹(一籠)しか乗らない
- 農夫がいないと、オオカミはヤギを食べ
ヤギはキャベツを食べる
状態:両岸にいる(ある)ものの配置
遷移:農夫が小舟で運ぶもの W, G, C。なければ F
開始状態:▷$\circled{\text{FWGC|}}$ 受理状態:$\dcircled{\text{|FWGC}}$
パズル.農法パズルの解を2つ示せ。
3で割り切れる2進数
$3$で割り切れる$2$進数を受理する有限オートマトンを考えてみよう。基本的なアイディアは
開始状態から$0,1$の列$w$で状態$q_k$に到達⇔2進数$w$の値を$3$で割った余りが$k$
となるようにすることである。
$2$進数$w$の値を$[w]_2$で表すと、$[w0]_2=2[w]_2,\ [w1]_2=2[w]_2+1$である。
パズル.上のアイディアに沿って、有限オートマトンを描け。
答 JFLAPファイル
正規集合⇒有限オートマトン
次の手順で有限オートマトンを構成する。- 与えられた文字列を受理する有限オートマトンを作る
- 2つの有限オートマトンから、それらが認識する文字列集合の連接を認識する有限オートマトンを作る
- 2つの有限オートマトンから、それらが認識する文字列集合の和集合を認識する有限オートマトンを作る
- 有限オートマトンから、それが認識する文字列集合の閉包を認識する有限オートマトンを作る
パズル:(a|b*c)*cを認識する有限オートマトンを示せ。
ヒント:有限オートマトンは開始状態と受理状態がそれぞれ1つで、開始状態への遷移と、受理状態からの遷移はないものを考えよう。
有限オートマトンと正規集合
定理.次の条件は同値⇒正規集合- 有限オートマトンで受理される
- 決定性有限オートマトンで受理される
- 正規表現で表される
定理.A,BがΣ上の正規集合ならば、A∪B, A∩B, Σ*-Aも正規集合である。
略証.A∪Bも正規集合なのは明らか。Aを認識する決定性有限オートマトンの受理状態と非受理状態を入れ替えた決定性有限オートマトンはΣ*-Aを認識する(Σ*はΣ上の文字列の全体を表す)。
パズル.文字列の集合Aに対し、ARをAの文字列を逆順にした文字列の集合とする。Aが正規集合ならARも正規集合であることを示せ。
決定性有限オートマトン(DFA)
辺のラベル(文字)の集合を$\Sigma$とする。有限オートマトンは次の条件を満たすとき決定性であるという。
$\varepsilon$遷移を持たず、すべての状態とラベル($\in\Sigma$)の組に対して、遷移先の状態が1つ
DFA(Deterministic Finite Automaton)では、
開始状態から与えられた入力(ラベル列)を持つ路は唯一つ(ある)
入力は、到達先の状態が受理状態なら受理、受理状態でなければ非受理
FAでは、
開始状態から与えられた入力(ラベル列)を持つ路は複数(または0個ある)
入力は、到達可能な状態の中に受理状態があれば受理、なければ非受理
注.状態とラベル($\in\Sigma$)の組に対し複数の遷移を許すものをNFA(非決定性有限オートマトン, Nondeterministic Finite Automaton)、さらに$\varepsilon$ラベルの遷移を許すものを$\varepsilon$-NFAと区別することもある。この授業でのFAは$\varepsilon$-NFA。
FA→DFAの変換
定理.FA$M$で認識可能⇒DFA$M_D$で認識可能略証.$M_D$を次のように作る。
- $M_D$の入力$w$で到達する状態:=$M$の$w$で到達可能な状態の集合
- $M_D$の開始状態:=$M$の開始状態から$\varepsilon$で到達可能な状態の集合
- $M_D$の受理状態:=$M$の受理状態を含む状態
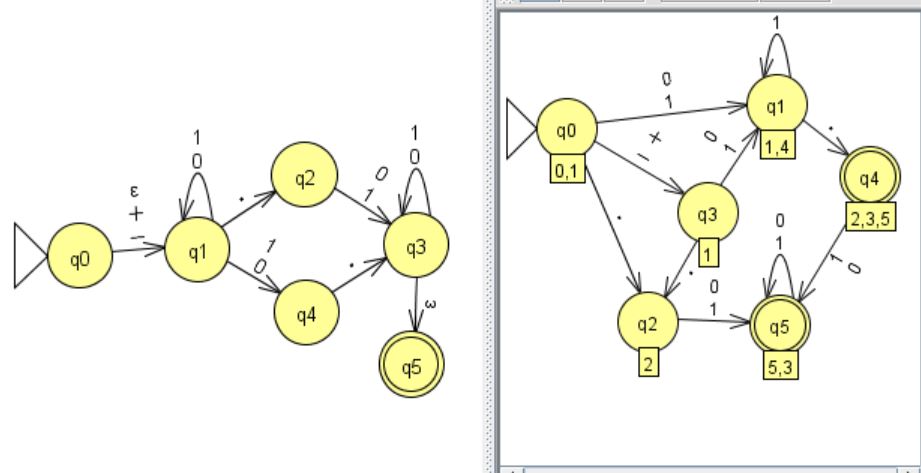 小数点(符号)を含む$2$進数を認識するFA(左図)とDFA(右図)
小数点(符号)を含む$2$進数を認識するFA(左図)とDFA(右図)DFAの最小化
DFAの状態$p,q$に対し$\transition{p}{w}\dcircled{ }\Leftrightarrow\transition{q}{w}\dcircled{ }$、即ちそれぞれを開始状態とみて同じ言語を認識する、ときに同値であるとする。定理.DFAの状態を、開始状態から到達不能な状態を除いて同値類に分割して得られるDFAは、同じ言語を受理する状態数最小のDFAである。
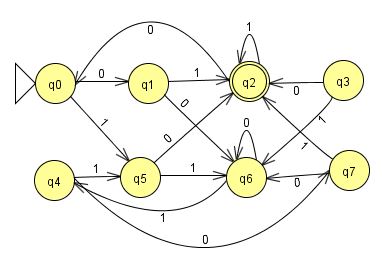

DFA(左図)とその最小化(右図):左図の状態q3は開始状態から到達不能なので除かれる(中央図)。